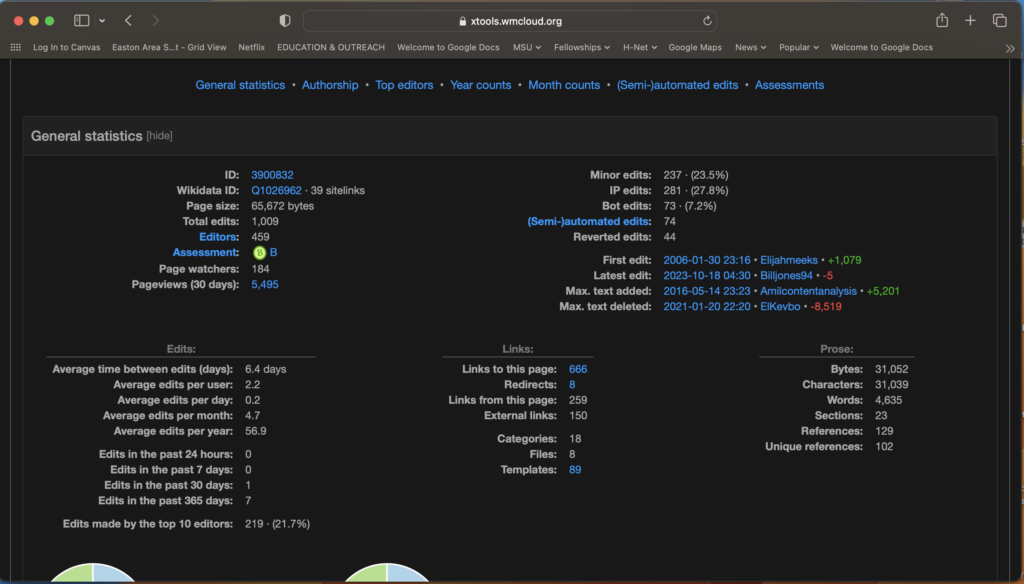
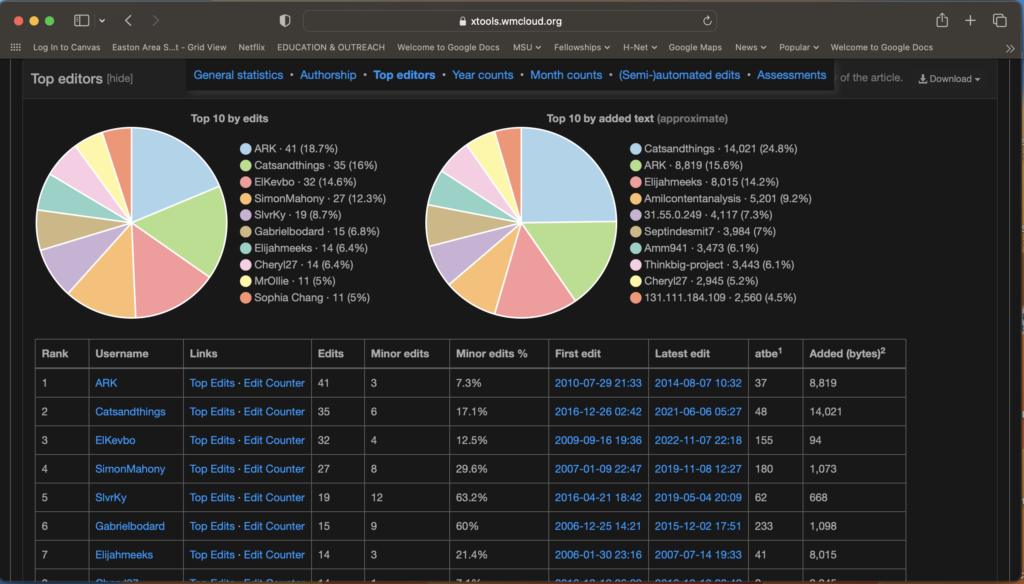
Working with Voyant was quite intimidating at first. In many ways, it confirmed the impressions I had formed from reading about other text mining projects, and about text mining in general.
Sources and Materials
Text mining allows scholars to works with large collections of text, what is technically called a corpus. By applying techniques of text mining to these collections, scholars can discern trends in the use of words and/or phrases. The advantage of using text mining techniques lies precisely in the amount of sources that can be “read” in a relatively short amount of time. For example, in the three projects examined during this module we saw that in the America’s Public Bible: A Commentary, (APBAC) the author looked at two major newspaper databases Chronicling America and Nineteenth Century U.S. Newspapers. Between these, the project used more than 13 million pages. Robots reading Vogue (RRV) used every issue published by Vogue, around 400,000 pages, plus 2700 covers. Signs@40 used the archive of the journal Signs from 1975 to 2014. In all three cases, no single human being would be able to read the entire corpora used in these projects in a single life-time.
However, not all large collections of text are equally useful or available for text mining. The use of computational methods for text mining requires that text collections are digitized using high quality techniques to minimize mistakes. Furthermore, text collections also need to be in the public domain, or potential authors should acquire necessary permissions for text mining.
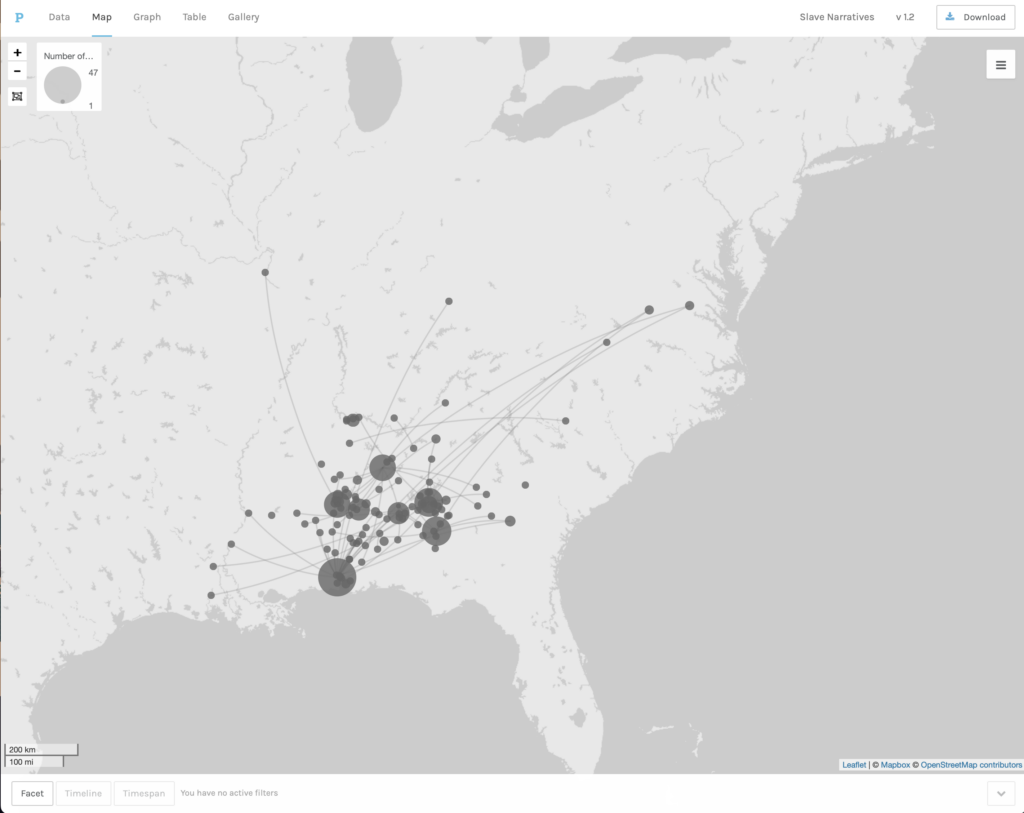
In our exercise with Voyant we worked with the WPA Slave Narratives which include more than two thousand interviews with former slaves conducted by staff of the Federal Writers’ Project of the Works Progress Administration. The materials were made available to us already cleaned and organized in 17 easy-to-use files. Having read how difficult and time consuming it can be to simply prepare a corpus for text mining, I was grateful to have this part of the process done for me. However, it is important to not forget that anyone hoping to embark on a text mining project will have to invest time and expertise on making sure the sources are adequately digitized and formatted.
What can we learn?
If one is lucky and/or persistent enough to secure the rights to a significant corpus, text mining can tell us several things about the text collection, the people who created it and organized it, and the world in which it originated. One common use of text mining is seeking trends in the usage of particular words or phrases. This is done in all three of the projects examined, although each uses this ability in different ways. For instance in APBAC, text mining is used to detect specific biblical passages. This allows the author to find out how often was a particular passage used and in what context. In RRV one can find two examples, Word Vectors and n-gram Search where text mining is used to discern the evolution of word usage overtime. Another use of text mining is topic modeling, this traces words used in a particular context to detect important topics within a set of texts. This is used prominently in Signs@40. In general, the text mining tools used in these projects tell us about the evolution of language, ideas and practices over a period of time as reflected in the pages of publications or documents.
Working with Voyant was a little confusing at first. It took me some time to understand how to manipulate the different visualizations and understand what they were telling me. However, once I started to get a better sense of what the tools allowed me to read, I started to see their potential. The Cirrus tool may seem like an oversimplification of a long and complex text. In some ways it is, but it is this ability to present a relatively simple image of what the text is about that makes it useful. One must remember that the goal of these visualizations is not to give us a deep analysis of what this vast amount of text says or means, its objective is to help us identify a few entry points, a few questions that one could explore when one is facing a large amount of documents. Many of the terms that appeared more frequently in the whole of the corpus were clearly a function of patterns of speech and regular conversation. Words like “old”, “house”, and “slaves” were among the most frequently used terms. However, when I started focusing either on individual terms, or on specific states and terms, I started to find some interesting things. For instance, the term “mother” appeared quite prominently in the general word cloud, but if one focused on the links to this word one saw that it was most frequently connected to words like “father”, “sold”, “died”, “married”, and “children”. These, quite literally, painted a picture. I could imagine tracing the phrases that include the word mother to investigate or illustrate how motherhood was experienced or remembered by former slaves.
What questions could we ask?
Text mining analysis allows us to answer primarily general questions about the contents of a large collection of documents. Since it focuses primarily on text, it can answer questions about how language is used, how people articulated their ideas and practices, and how all of these evolved overtime. However, one has to cultivate a healthy skepticism when working with text mining techniques. First, anyone’s ability to identify meaningful entry points into a large corpus is limited or enhanced by their understanding of the historical and historiographical context in which those sources were created. In this regard, for instance, it was useful to know that there is a body of research that has investigated the experiences of female slaves and that, this historiography has given particular attention to motherhood. I am not a expert on this field, but I knew enough to know that following that term could lead to some interesting questions. A second factor that can affect the questions we could ask from text mining has to do with the chronological or geographical coverage of the collection in question. Some of the collections used in the projects examined in this model covered a no less than forty years. This meant that those working on those collections could ask questions about change or continuity over time. The Slaves Narratives collection was different in that, chronologically, it covered a relatively short period. Even though the memories that interviewers tried to elicit went back many years, the actual interviews were collected during a span of only two years. However, the interviews covered a large portion of the country. Seventeen states were represented in the dataset we used. In light of this, the nature of the questions one can reasonably ask from these interviews is quite different. Rather than focusing on how themes may have changed over time, one would ask how do interviews in one state are different from another?
For instance, using Voyant, I found it very useful to identify differences between the collections that could tell us more about the how the interviews were collected and how to read them. One exercise that was particularly useful was looking at the distinctive terms identified in two sets of documents. One of the states I examined was Florida, here I examined ten distinctive terms. It was interesting that three of these were names of places located in Florida and two were Family names. I thought this would be quite typical of all collections, but when I examined the interviews from Georgia, I was surprised that most of the distinctive terms in those interviews were related to dialect, only one was the name of a place, and there were no family or private names. One would need to investigate these collections further to account for these differences.
Historians typically divide sources between primary and secondary, and this distinction determines the kinds of questions they can ask. It is not news to any experienced historian that sources such as the Slave Narratives are difficult to place in either one of these buckets. Working with Voyant, however, highlights the importance of understanding when and how the Slave Narratives can be used as primary sources and when and how they can serve as secondary sources. Since text mining allows us to capture the totality of a corpus and then break it down in smaller pieces, one should be careful that in trying to put it back together one does draw connections that may not be warranted by the historical or historiographical context.
In the hands of a patient and knowledgeable historian, Voyant and text mining in general, can be powerful tools. Despite the care and time one needs to invest in acquiring rights, cleaning data, testing algorithms, etc. Text mining makes it possible to examine what otherwise would be an impossibly large amount of text, and thus offers a different perspective on one of the oldest and most valuable expressive and communication tools we have: words.