Network visualization projects allow users to observe the amount and overall shape of connections between individuals, institutions, locations, etc. The information used to document these connections can be extracted from different types of digitized materials. Arguably, the power of this type of visualization lies in its ability to highlight patterns a of discreet connections that are not easy to discern in large text corpora.
Working with Palladio made it possible to see more clearly the strengths and weaknesses of network visualizations. One point that was made very clear in the readings, and in the projects we examined, is that this type of visualizations require a careful and informed preparation of the data that is to be used. For this example, we were given three csv. files from the WPA Slave Narratives project that had been prepared to be used with Palladio. Even with this clear advantage, it took me a good forty minutes to upload the files. Every time I tried to load a file I got a message alerting me to an error in one of the lines. But I could not figure out what the error was. In the end, I decided not to use a downloaded file, but I simply opened it directly from the link and copied and pasted the contents into Palladio. Somehow, this did the trick and I was able start the work. This was just a good example of how useful it is to understand the requirements of the software and the ways in which data should be presented.
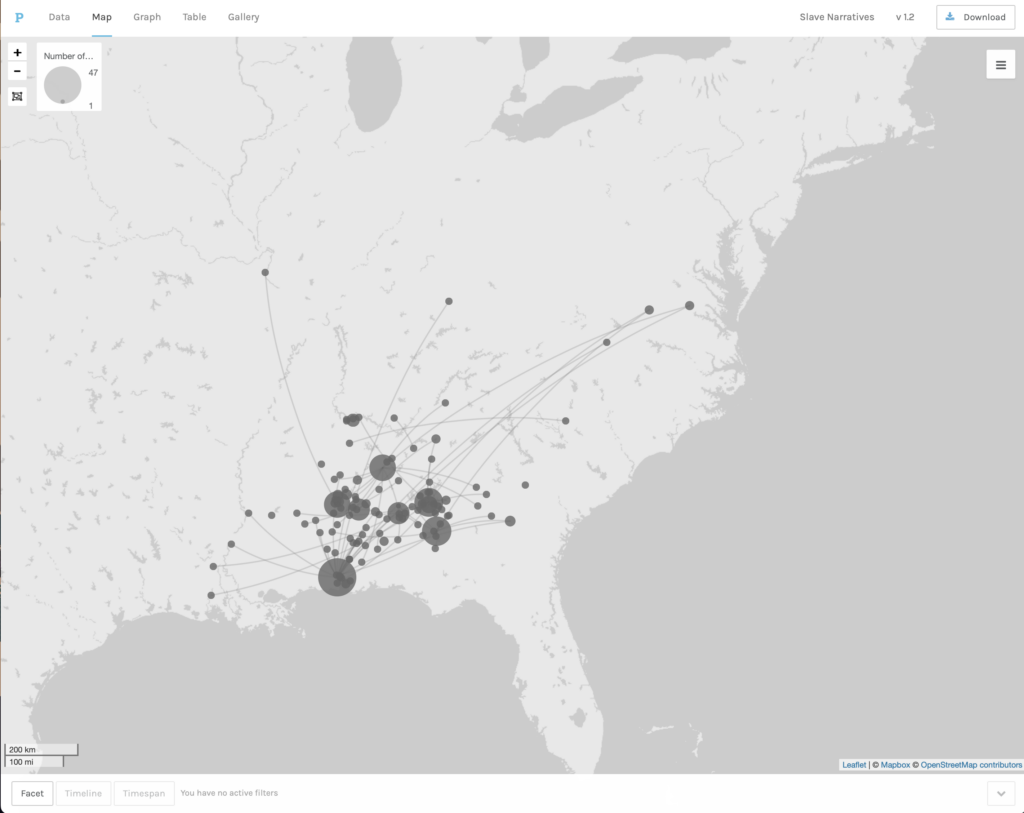
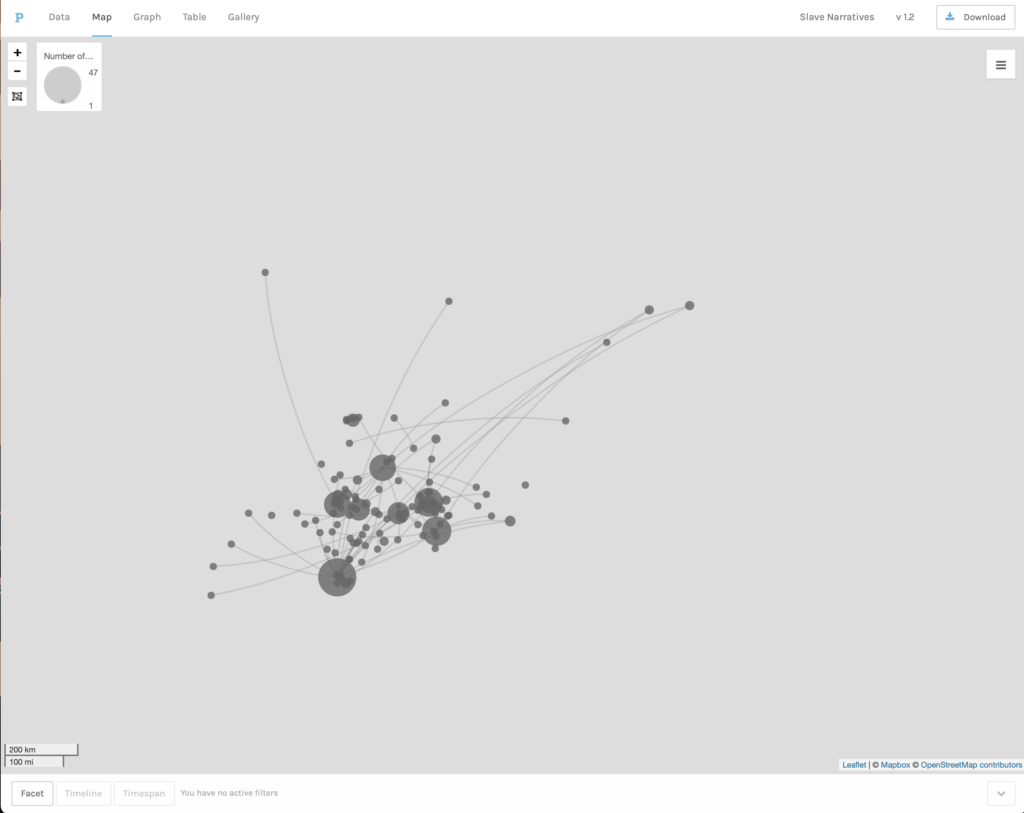
For our first exercise we were asked to do a map visualization. In this case, we were to connect the place where interviewees had been enslaved with the place where they were interviewed. The first map visualization used the background of a land map, which was useful to get an idea of how far or how close former slaves had worked before they moved to Alabama. The map showed that the majority of slaves interviewed in Alabama had been enslaved relatively closely to where they were interviewed. Very few came from further north. The second visualization removed the map base, leaving an image that resembled more a network graph, but without a what nods and edges represented. This was a good way of understanding better the differences between a map visualization and a network graph and the possibilities of each of these tools.
A third exercise asked us to produce a network graph. In this case, the particular features of the network visualization (the ability to highlight one type of nod, to make them bigger or smaller depending on the number of interviews) made the visualization more useful to discern the how many slaves interviewed in particular Alabama locations had come from other places. By focusing on some of the larger nods, a researcher could find some meaningful patters about the movement of slaves during the years after emancipation. However, I have to admit that my knowledge of the historiography on this question only allowed for some general observations, which, in this case confirmed what we had seen in the map, that slaves came from many different places, but mostly had not moved very far from where they had been enslaved.

These exercises illustrate what can be both a weakness and a strength of network visualization. Network graphs can tell a lot of information about discreet types of data, but they can only handle so many variables at one time, a very large volume of information can produce a visualization that is difficult to read. However, Palladio allows users to filter some of the data that goes into a visualization. For instance, we were asked to create a graph that illustrated the relationship between Interviewers and Interview Subjects. We were then able to use facets to further filter the data that went into the visualization. In this case we chose to filter by Gender and Type of Work. I was not able to discern any particular patterns from this exercise, but it showed that the strength of network analysis relies on its ability to focus one’s attention on specific types of connections. Some will prove to be very revealing, while others much less so. But the possibility of changing the elements of the graph and exploring different configurations is where the possibilities of Palladio proved most useful.
Needless to say, however, the power and flexibility of the tool is largely contingent on the data that is used. The last set of exercises confirmed both that network analysis allows for very interesting explorations of data, but also that such data needs to be already rich and adequately formatted to allow for a successful exploration. In the last set of exercises we created network graphs that connected gender, type of work, age, and interviewer to the topics that were explored in the interviews. The different visualizations generated showed that neither of these factors seemed to have a dramatic impact on the topics addressed by former slaves. However, these observations are based on the general overall visualizations. Subtle differences may yet to be discovered if we were to further filter the data. Which brings me back to the factors that can make or break this kind of tool, first the quality and richness of the data itself, and the level of expertise of those designing and using the tool.
Could this not be asked of any other research project, digital or otherwise? Is the expense and preparation invested in this kind of project proportional to the time saved or the potential findings? In my original review I concluded that it is not always clear that the research gains justify the investment involved in creating and deploying this kind of tool. However, I also observed that what is gained may be of a different nature. Network analysis tools are not tools for the public historian hoping to bring historical thinking and historical sources to a larger public. These are sophisticated tools of analysis that should be developed by experts for experts. Their design and use require serious understanding of the sources and historiography. I am sure that had I been better versed in the history of slavery and emancipation in Alabama, some of these visualizations would have been much more meaningful to me. My experience working with Palladio, however, encouraged me to be a better historian, to be more thoughtful and intentional about the questions I ask, more careful about the assumptions I make about my evidence, and ultimately, more flexible and creative about how sources can help answer old and new questions. As it was stated repeatedly in our readings, network visualizations are not here to replace the exercise of reading through sources or becoming familiar with historiography, they are here to make us better thinkers and users of sources and historiography.