The tools examined during the past three modules, Voyant, Kepler, and Palladio, allowed for different levels of data analysis and visualization. One could see these tools are serving different needs dictated by the kind of data-set that need to examined. Voyant enables researchers to text-mine large volumes of mostly unstructured text. Kepler produces map visualizations that require files that have been tagged for geographical locations. Palladio creates network visualizations that required highly structured files.
One could say that Voyant offered the opportunity of a relatively open-ended exploration of the WPA Slave Narratives.As a text mining tool, Voyant proved to be very effective when examining a large volume of relatively unstructured data. The five tools included in Voyant (Cirrus, Reader, Trends, Summary and Contexts) provide different entry points into the data and different ways in which said data could be re-organized, explored and visualized. Although Voyant is largely meant to be used by researchers, I can also see how it could be used by public historians, museum professionals and teachers. The Cirrus tool, for instance, produces powerful visualization that can enrich lectures and exhibits. In contrast, I found the Trends tool more difficult to manipulate and read. It was easy to see how many times a word would appear in the different State collections, but I could not easily explore other kinds of trends such chronological distribution, age or gender. These limitations are understandable given that text mining seeks for individual words or groups of words, and not for categories of words.
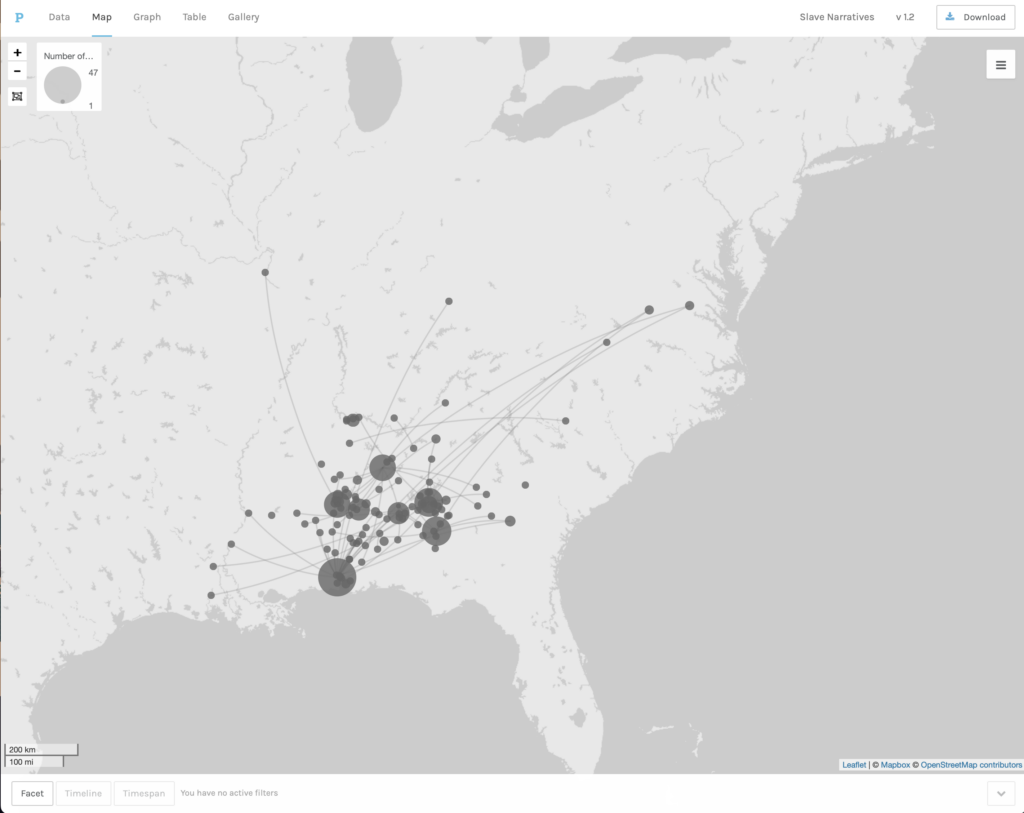
Kepler used more structured data than the one used in Voyant. For this reason, we were able to illustrate different aspects of the WPA Slave Narratives. The maps we produced, using geo-tagged CSV files, allowed us to see the relative volume of interviews done in a particular region. It was also possible to create a map that presented a timeline. Yet, the visualizations produced with Kepler did not give us any idea about the content of the interviews. Thus, I found Kepler to be a very good complement to Voyant. While Voyant provided us with the possibility of analyzing the content of the interviews, Kepler enabled us to visualize the broader geographical and chronological context in which the interviews were performed. Also, I found the visualizations created with Kepler were easier to read and manipulate than those produced to Voyant. This is not a criticism of the effectiveness of Voyant. When working with Kepler we used a smaller and more structured data-set prepared to answer more focused questions about time, place and volume; while Voyant was meant to facilitate a more open ended exploration of the ideas contained in a much larger set of documents.
The last tool we used was Palladio, a network analysis and visualization tool. From all the tools examined, Palladio required the most rich and structured data-set. The goal of this tool is to allow researcher to identify patterns of connection or relationships between different categories of data. Palladio was very effective when producing visualization of different types of relationships. For instance, we are able to create a map where we saw where slaves had been enslaved in relation to where they were interviewed. We were also able to illustrate connections between the topics addressed in the interviews and the gender, age, or type of work of former slaves. In this regard, Palladio proved to be the most flexible of all three tools in terms of the kinds of questions it could help researchers explore. But the power of the tool was only made possible by the quality of the data and the way in which it was structured.
Experimenting with these tools made me more aware of the challenges and potential inherent to the use of digitized sources. Ultimately, the use of any of these tools will require that data is digitized and structured to some degree and in light of particular questions. For this reason, I think it is important to have different types of tools that work with different types of files. Tools that allow for more open-ended questions like Voyant, or for a more focused exploration like Palladio. In either case, the larger challenge is to ensure that the digitization and preparation of the data is done thoughtfully and professionally. The ultimate effectiveness of any of these tools will largely depend on the quality of the data and the expertise of the researchers using it.