Back in the mid-1990s, as an undergraduate student, I participated in a project where we were recruited to make an inventory of Mexican history secondary sources available in the public and private libraries located in Mexico City. We were all given a long a long list of books and we were charged with visiting one library, determine whether there were copies of the listed books in the library assigned to us, and add other sources that were not included in the original list. At the time, only a few academic libraries had digitized their catalogues and, in most cases, the process was still ongoing. What was still not available was the possibility to search these catalogues remotely. Thus, the goal of our project was to produce a bibliography that could allow students and researchers to locate particular sources without having to spend time visiting different libraries throughout the city. A project like this became unnecessary when digital catalogues were made available online. In this case, technology was able to solve one problem, but crowdsourcing remains a useful approach for processes and activities for which modern technology has not been able to provide solutions.
In my last post I talked about how AI chatbots, such as ChatGPT, were the latest technological response to the question of how to process vast amounts of information. Despite the progress that AI technology has achieved, it seems clear that there are still good reasons to continue using human beings in the process of producing knowledge. The idea of using large numbers of people to collect or process large bodies of documents, sources or data is not new. As my experience shows, this approach has been useful when the volume of the materials that needed to be processed was too large, and the nature of the work did not require too much training or expertise. The advent of digital technologies has made it possible to reach more people as potential contributors. Also, the increasing digitization of documents and other types of sources has created a (hopefully) virtuous circle in which crowdsourcing can be used as a means to increase access to historical and cultural materials and, by creating greater access, it can also encourage more engagement from the public.
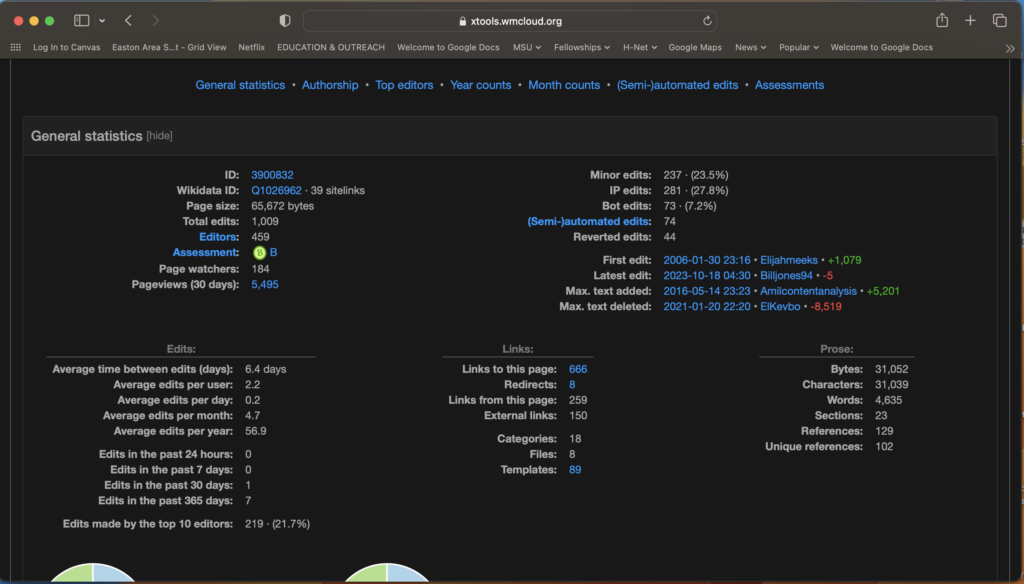
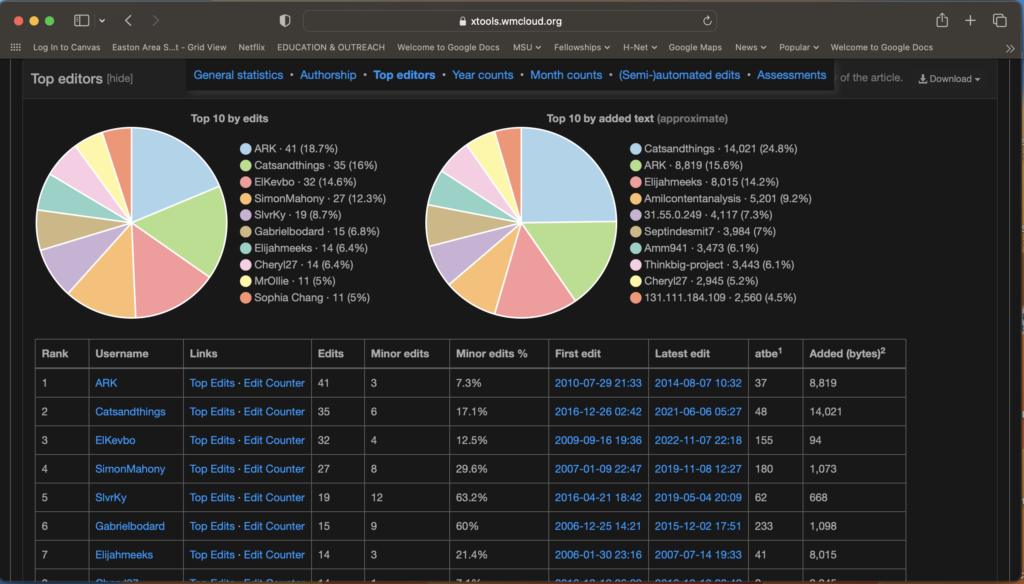
As we have seen in this module, crowdsourcing is useful to open the process of knowledge production to a wider public. This can be done by asking people to write and edit entries in a project such as Wikipedia, or to contribute individual experiences during a particular event, as was possible in the September 11 Digital Archive. In both cases, members of the public are instructed to work under a set of rules, but are otherwise encouraged to be part of a collective exercise of data collection and interpretation. In these cases, technology has made it possible to reach a larger number of people while also lowering the barriers for their participation.
Other uses for crowdsourcing involve the processing of large volumes of material that cannot be achieved using computers. Projects of transcription such as Transcribing Bentham, or description of photographs such as Nasa on the Commons, emanate from the need to make materials more accessible through digitization. But this goal also requires the infrastructure by which documents and images can be more accurately catalogued, searched, and studied. Current technology enables us to publish digital photographs and documents on library and museum websites; but it is not yet capable to read all types of handwriting or describe the contents of a photograph. For these, we still need people. So it is not surprise that some large digitization projects are often accompanied by a crowdsourcing component. An example of this is Linked Jazz where members of the public are asked to characterize the relationships that were described in the interviews with Jazz artists.
Thus, projects that lend themselves to a crowdsourcing approach will typically involve the creation or processing of large volume of materials, where contributors need little or no expertise, and that are aimed at expanding access to the process of knowledge production. Transcription, basic annotation and description, collection, are processes that, under the right planning and circumstances, can be achieved through crowdsourcing.
Careful planning does make a difference to the success of crowdsourcing projects. First, it is important to cast a wide enough net to reach as many people as possible. Second, it is vital to create the infrastructure and incentives that can keep contributors engaged. This is best achieved when a project can explain how the use, preparation and processing of sources lies at the foundation of knowledge production; thus turning what are often seen as meaningless tasks into essential steps in the preservation, dissemination and interpretation of sources. By allowing people access to sources that would normally be reserved to specialists, crowdsourcing projects start by establishing a relationship of trust that is further enhanced when contributors are entrusted to re-tell, read, transcribe, describe or interpret. This trust, however, can be intimidating if contributors do not feel supported and confident that they will have the time to learn while on the job. Thus, it is vital that crowdsourcing projects develop mechanisms for support and communication with contributors and interfaces that are easy to use. But the most important incentive, in my view, is the feeling that by committing to a task, contributors can develop expertise and the value of their work will continue to increase. I believe this cultivates greater engagement and ownership of the overall project.
Ultimately, the success of crowdsourcing projects can be measured by their ability to engage the public in the process of knowledge production. If contributors feel they can enhance their skills and are empowered to make meaningful contributions, they will remain committed to the value and success of the larger project